TrackerGuru Developer Guide
Acknowledgements
This project is based on the AddressBook-Level3 project created by the SE-EDU initiative.
Libraries used:
Tools used:
- Gradle - For build automation and dependency management
- PlantUML - For UML diagram generation
- MarkBind - For generating the project documentation website
- CheckStyle - For code style checking
Documentation:
- The structure and format of this Developer Guide is adapted from the AB3 Developer Guide
Setting up, getting started
Refer to the guide Setting up and getting started.
Design
Architecture
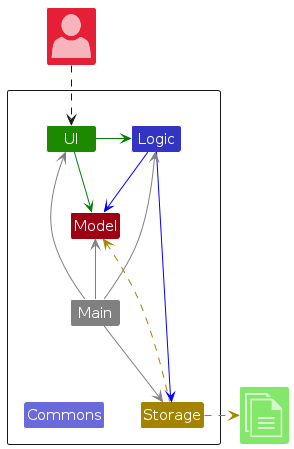
The Architecture Diagram given above explains the high-level design of the App.
Given below is a quick overview of main components and how they interact with each other.
Main components of the architecture
Main (consisting of classes Main and MainApp) is in charge of the app launch and shut down.
- At app launch, it initializes the other components in the correct sequence, and connects them up with each other.
- At shut down, it shuts down the other components and invokes cleanup methods where necessary.
The bulk of the app's work is done by the following four components:
UI: The UI of the App.Logic: The command executor.Model: Holds the data of the App in memory.Storage: Reads data from, and writes data to, the hard disk.
Commons represents a collection of classes used by multiple other components.
How the architecture components interact with each other
The Sequence Diagram below shows how the components interact with each other for the scenario where the user issues the command delete 1.
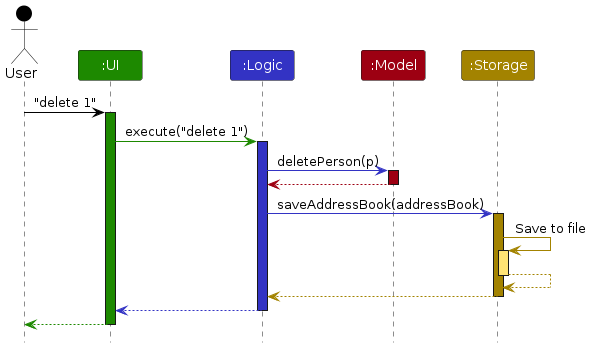
Each of the four main components (also shown in the diagram above),
- defines its API in an
interfacewith the same name as the Component. - implements its functionality using a concrete
{Component Name}Managerclass (which follows the corresponding APIinterfacementioned in the previous point).
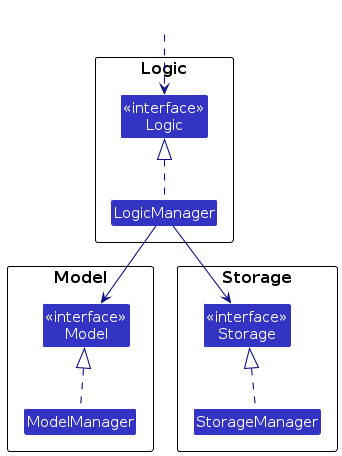
For example, the Logic component defines its API in the Logic.java interface and implements its functionality using the LogicManager.java class which follows the Logic interface. Other components interact with a given component through its interface rather than the concrete class (reason: to prevent outside component's being coupled to the implementation of a component), as illustrated in the (partial) class diagram below.
The sections below give more details of each component.
UI component
The API of this component is specified in Ui.java
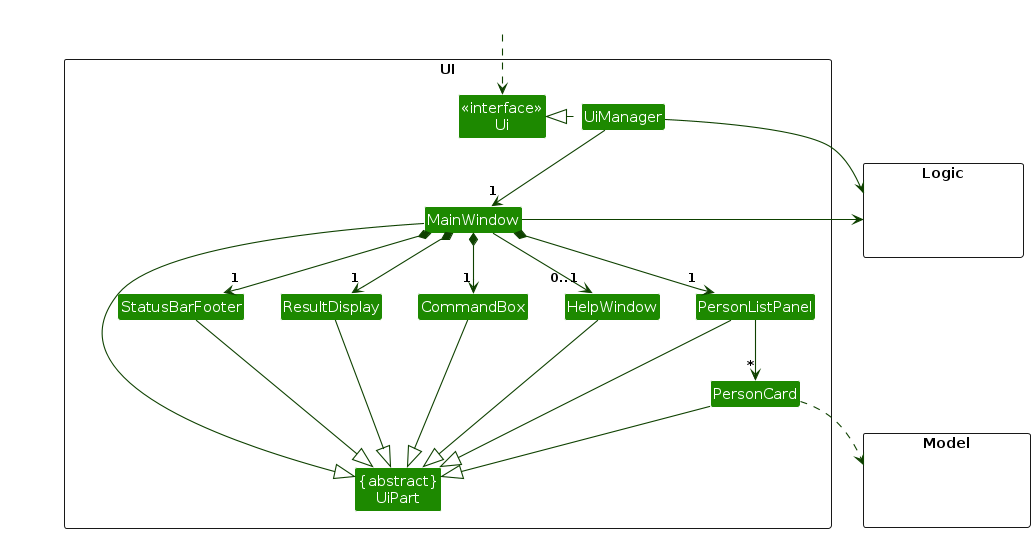
The UI consists of a MainWindow that is made up of parts e.g. CommandBox, ResultDisplay, PersonListPanel, StatusBarFooter etc. All these, including the MainWindow, inherit from the abstract UiPart class which captures the commonalities between classes that represent parts of the visible GUI.
The UI component uses the JavaFx UI framework. The layout of these UI parts are defined in matching .fxml files that are in the src/main/resources/view folder. For example, the layout of the MainWindow is specified in MainWindow.fxml
The UI component,
- executes user commands using the
Logiccomponent. - listens for changes to
Modeldata so that the UI can be updated with the modified data. - keeps a reference to the
Logiccomponent, because theUIrelies on theLogicto execute commands. - depends on some classes in the
Modelcomponent, as it displaysPersonobject residing in theModel.
Logic component
API : Logic.java
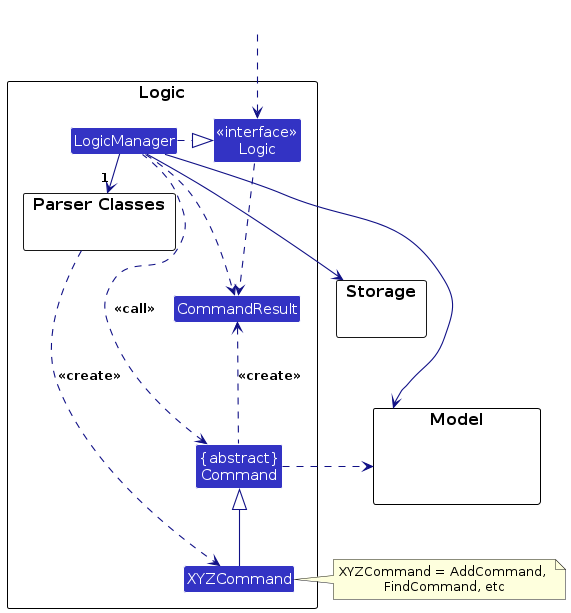
Here's a (partial) class diagram of the Logic component:
The sequence diagram below illustrates the interactions within the Logic component, taking execute("delete 1") API call as an example.
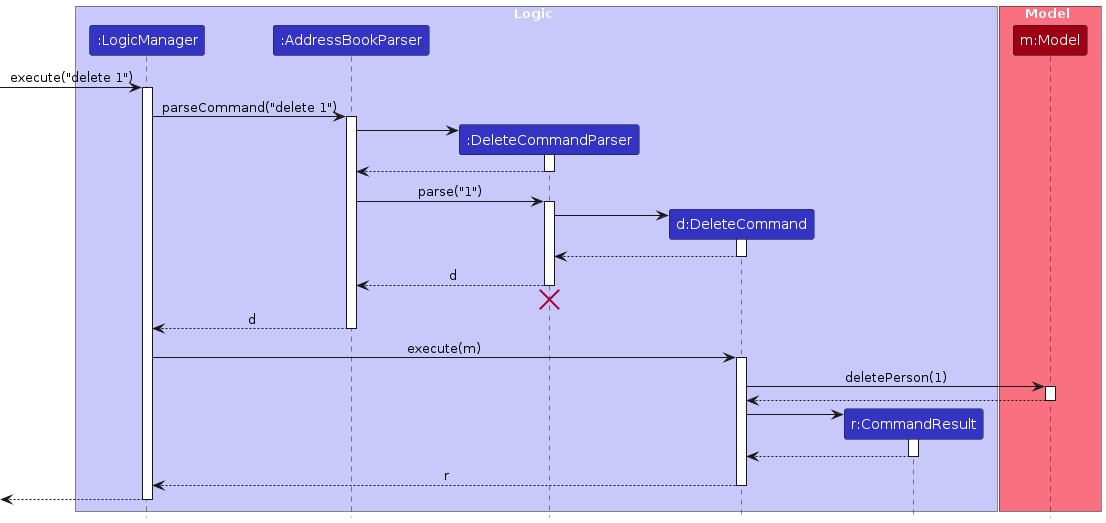
Note: The lifeline for DeleteCommandParser should end at the destroy marker (X) but due to a limitation of PlantUML, the lifeline continues till the end of diagram.
How the Logic component works:
- When
Logicis called upon to execute a command, it is passed to anAddressBookParserobject which in turn creates a parser that matches the command (e.g.DeleteCommandParser) and uses it to parse the command. - This results in a
Commandobject (more precisely, an object of one of its subclasses e.g.DeleteCommand) which is executed by theLogicManager. - The command can communicate with the
Modelwhen it is executed (e.g. to delete a person).
Note that although this is shown as a single step in the diagram above (for simplicity), in the code it can take several interactions (between the command object and theModel) to achieve. - The result of the command execution is encapsulated as a
CommandResultobject which is returned back fromLogic.
Here are the other classes in Logic (omitted from the class diagram above) that are used for parsing a user command:
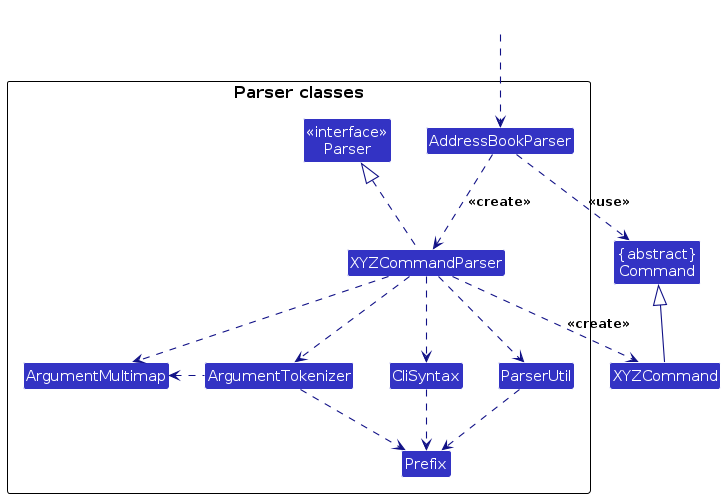
How the parsing works:
- When called upon to parse a user command, the
AddressBookParserclass creates anXYZCommandParser(XYZis a placeholder for the specific command name e.g.AddCommandParser) which uses the other classes shown above to parse the user command and create aXYZCommandobject (e.g.AddCommand) which theAddressBookParserreturns back as aCommandobject. - All
XYZCommandParserclasses (e.g.AddCommandParser,DeleteCommandParser, ...) inherit from theParserinterface so that they can be treated similarly where possible e.g, during testing. - Note: Some commands like
ListCommand,StatsCommand,ClearCommand,ExitCommand, andHelpCommanddo not require parsers as they take no parameters.
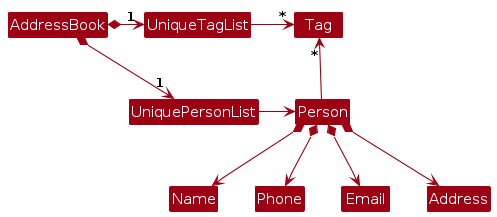
Model component
API : Model.java
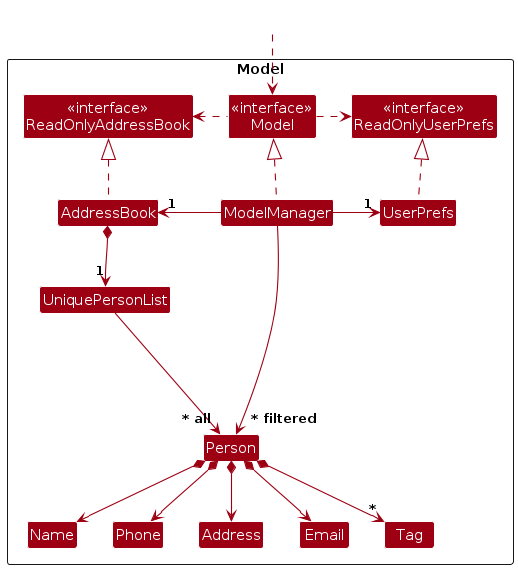
The Model component,
- stores the address book data i.e. all
Personobjects (which are contained in aUniquePersonListobject). - stores the currently 'selected'
Personobjects (e.g. results of a search query) as a separate filtered list which is exposed to outsiders as an unmodifiableObservableList<Person>that can be 'observed' e.g. the UI can be bound to this list so that the UI automatically updates when the data in the list change. - stores a
UserPrefobject that represents the user’s preferences. This is exposed to the outside as aReadOnlyUserPrefobjects. - does not depend on any of the other three components (as the
Modelrepresents data entities of the domain, they should make sense on their own without depending on other components)
Note: An alternative (arguably, a more OOP) model is given below. It has:
- A Tag list in the
AddressBook, whichPersonreferences - A Role list in the
AddressBook, whichPersonreferences - A TagGroup set in the
AddressBook, whichTagoptionally references
This allows AddressBook to:
- Only require one
Tagobject per unique tag, instead of eachPersonneeding their ownTagobjects - Only require one
Roleobject per unique role, instead of eachPersonneeding their ownRoleobjects - Maintain a centralized collection of
TagGroupobjects for organizing tags into categories (e.g. "PropertyType", "Location")
Tags can optionally belong to a TagGroup, enabling structured organization and group-based filtering of contacts.
Storage component
API : Storage.java
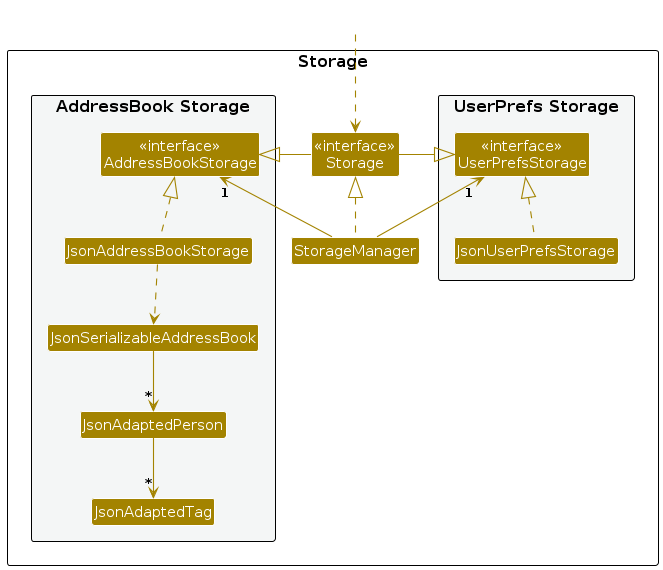
The Storage component,
- can save both address book data and user preference data in JSON format, and read them back into corresponding objects.
- inherits from both
AddressBookStorageandUserPrefStorage, which means it can be treated as either one (if only the functionality of only one is needed). - depends on some classes in the
Modelcomponent (because theStoragecomponent's job is to save/retrieve objects that belong to theModel)
Address book data is persisted as a JSON file through JsonSerializableAddressBook, which contains:
A list of
JsonAdaptedPersonobjects (each containingJsonAdaptedTagandJsonAdaptedRoleobjects)A list of
JsonAdaptedTagGroupobjects representing tag categories
This structure enables centralized storage of Tag Groups alongside person data, maintaining consistency with the Model component's Tag Group management.
Common classes
Classes used by multiple components are in the seedu.address.commons package.
Implementation
This section describes some noteworthy details on how certain features are implemented.
Duplicate Handling
Implementation
The duplicate handling mechanism ensures that no two contacts in the address book can have the same phone number or email. This is important for property agents who need to maintain unique contact information for each client, as these fields serve as critical identifiers for communication and identification.
The feature is implemented through checks in the Model component, specifically:
Model#hasSamePhoneNumber(Person person)— Checks if any existing person in the address book has the same phone number as the given person.Model#hasSameEmail(Person person)— Checks if any existing person in the address book has the same email as the given person.
These operations are exposed in the Model interface and implemented in ModelManager, which delegates the checks to AddressBook and ultimately to UniquePersonList.
Given below is an example usage scenario and how the duplicate handling mechanism behaves. For illustration purposes, we will use phone number as the example, though the same logic applies to email checks.
Step 1. The user attempts to add a new contact John with phone number 12345678 by executing the command add n/John p/12345678 e/john@example.com a/123 Street r/Buyer s/Pending. The AddCommand is created and executed.
Step 2. During execution, AddCommand performs duplicate validation checks for phone number and email.
- Checks for duplicate phone number by calling
Model#hasSamePhoneNumber(toAdd)(illustrated in the sequence diagram below) - Checks for duplicate email by calling
Model#hasSameEmail(toAdd)
Each check cascades through the components:
ModelManagercalls the correspondingAddressBookmethod (e.g.AddressBook#hasSamePhoneNumber(person))AddressBookcalls the correspondingUniquePersonListmethod (e.g.UniquePersonList#containsPhoneNumber(person))UniquePersonListiterates through all persons to check if any existing person has the same field value
Step 3. If any of the checks return true (e.g. the phone number 12345678 already exists belonging to another contact Alice), AddCommand throws a CommandException with an appropriate error message such as "This phone number already exists in the address book".
Step 4. If all checks pass (return false), the new contact is successfully added to the address book.
The following sequence diagrams show how the duplicate phone number check works during the execution of an add command (the same pattern applies to email checks):
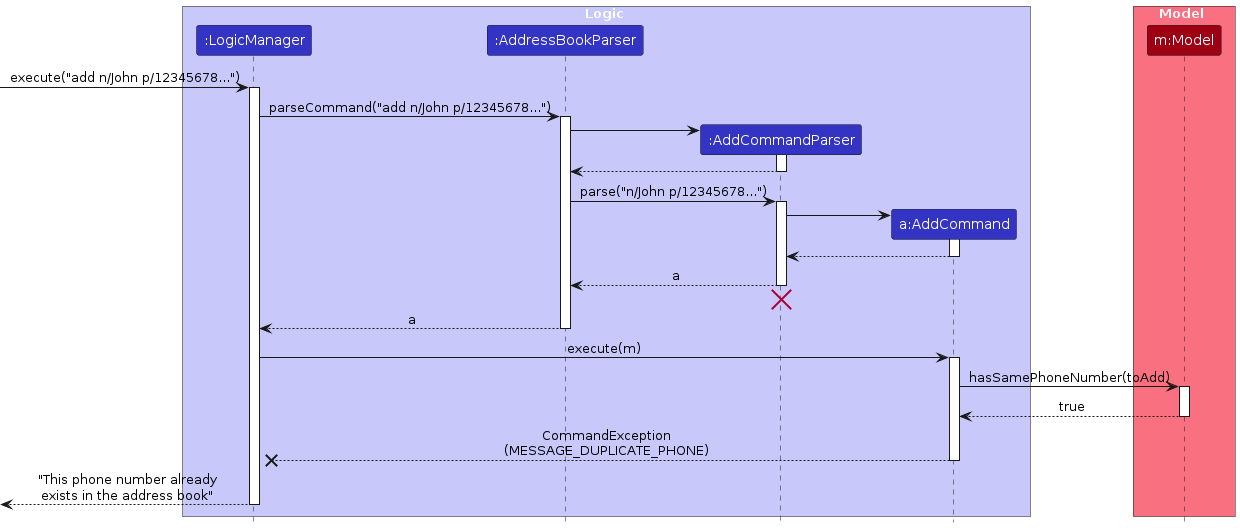
Note: The lifeline for AddCommandParser should end at the destroy marker (X) but due to a limitation of PlantUML, the lifeline continues till the end of diagram.
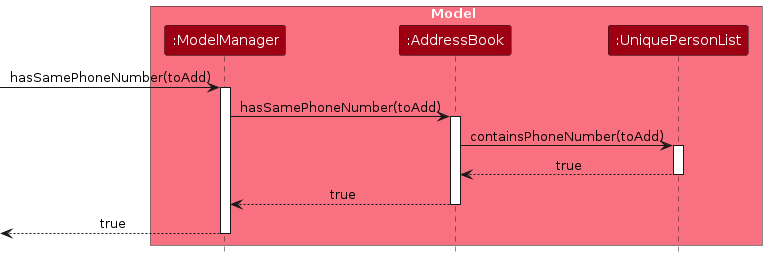
Note: Name duplication is not checked because property agents may legitimately have multiple contacts with the same name (e.g. common names like "John Tan"). Phone numbers and emails are more reliable unique identifiers for contact management.
Design considerations:
Aspect: When to perform the duplicate field checks:
Alternative 1 (current choice): Check during command execution in
AddCommandandEditCommand.- Pros:
- Simple and straightforward implementation.
- Error detection happens at the business logic layer, providing clear feedback to users.
- Consistent with existing duplicate person checking mechanism.
- Allows for specific error messages for each field type.
- Cons:
- The checks are performed separately in multiple command classes, leading to some code duplication.
- Pros:
Alternative 2: Enforce uniqueness constraints at the
UniquePersonListlevel.- Pros:
- Centralized validation logic in the model layer.
- Automatically applies to all operations that modify the person list.
- Cons:
- Less control over error messages for different commands.
- Pros:
Aspect: Scope of the uniqueness checks:
Alternative 1 (current choice): Phone numbers and emails must be globally unique across all contacts.
- Pros:
- Prevents confusion and data integrity issues.
- Aligns with real-world expectation that these fields uniquely identify individuals.
- Simplifies contact management for property agents who rely on these identifiers.
- Cons:
- May be overly restrictive in some scenarios.
- Pros:
Alternative 2: Allow duplicate fields but warn the user.
- Pros:
- More flexible for edge cases.
- Still alerts users to potential data entry errors.
- Cons:
- May lead to confusion when the same contact information appears for multiple people.
- Could result in unintended duplicates if users ignore warnings.
- Pros:
Tag Group Management feature
Overview
The Tag Group Management feature allows users to organize tags into logical categories (Tag Groups). This helps property agents categorize and manage their contacts more effectively by grouping related tags together (e.g. propertyType, location, priceRange).
Tag Groups provide the following benefits:
- Better organization: Group related tags together for easier management
- Improved filtering: Filter contacts by Tag Group categories
- Clearer structure: Instantly see which category each tag belongs to
Tag Validation
Regex Patterns:
Standalone tags:
^[a-zA-Z0-9]+$- Alphanumeric only, no spaces
- Example:
VIP,priority
Grouped tags:
^([a-zA-Z0-9]+)\.([a-zA-Z0-9][a-zA-Z0-9.\-_]*)$- GROUP:
[a-zA-Z0-9]+(alphanumeric only) - Separator: Exactly one dot (
.) - VALUE:
- Must start with alphanumeric:
[a-zA-Z0-9] - Can contain:
[a-zA-Z0-9.\-_]*(alphanumeric, dots, hyphens, underscores)
- Must start with alphanumeric:
- Example:
priceRange.1.5M-2M
- GROUP:
This relaxed validation for VALUES allows property agents to use more descriptive tag values like 500k-1M, 1.5M-2M, or Bishan-North.
Implementation
The Tag Group Management feature is implemented through multiple layers of the application:
Model Layer
Core Classes:
TagGroup: Represents a Tag Group with an alphanumeric name. Ensures immutability and validates names using regex patterns.Tag: Modified to optionally reference aTagGroup. Tags can exist independently or be associated with a group.AddressBook: Maintains aSet<TagGroup>to store all created Tag Groups. Provides methods to add, remove, and check Tag Groups.Modelinterface: Exposes operations for Tag Group management (addTagGroup,deleteTagGroup,hasTagGroup,isTagGroupInUse).
Key Methods:
Model#addTagGroup(TagGroup): Adds a new Tag Group to the address book if it doesn't already exist.Model#deleteTagGroup(TagGroup): Removes a Tag Group from the address book after validation.Model#hasTagGroup(TagGroup): Checks if a Tag Group exists in the address book.Model#isTagGroupInUse(TagGroup): Checks if any person's tags reference the specified Tag Group. Uses Java Streams withflatMap()andanyMatch()for efficient checking.
Logic Layer
Command Classes:
TagGroupCommand: Creates a new Tag Group or lists all existing Tag Groups. Handles both parameterized (create) and parameterless (list) executions.DeleteTagGroupCommand: Deletes a Tag Group after checking that it's not in use by any person's tags.
Parser Classes:
TagGroupCommandParser: Parses user input for thetgcommand. Distinguishes between listing (no arguments) and creating (with GROUP_NAME argument).DeleteTagGroupCommandParser: Parses user input for thedtgcommand and validates the Tag Group name.
Command Execution Flow:
- User enters a Tag Group command (e.g.
tg propertyType) AddressBookParserroutes to the appropriate parser- Parser validates input and creates the command object
- Command executes by interacting with the
Model - Result is returned to the UI layer
Storage Layer
Storage Classes:
JsonAdaptedTagGroup: Jackson-friendly adapter class forTagGroupserialization/deserialization.JsonSerializableAddressBook: Extended to include aList<JsonAdaptedTagGroup>field for persisting Tag Groups.
Persistence Flow:
- Tag Groups are serialized to JSON alongside persons in
addressbook.json - On application startup, Tag Groups are deserialized and loaded into the
AddressBook - Tag Groups persist across sessions automatically
Usage Scenarios
Scenario 1: Creating a Tag Group
User Goal: Create a Tag Group called propertyType
Steps:
- User executes
tg propertyType AddressBookParsercreates aTagGroupCommandParserTagGroupCommandParserparses the input and creates aTagGroupCommandwith the group nameTagGroupCommand#execute()checks if the Tag Group already exists usingModel#hasTagGroup()- If it doesn't exist,
Model#addTagGroup()is called to add the Tag Group - Success message "Tag Group created: propertyType" is displayed to the user
Sequence Diagram:
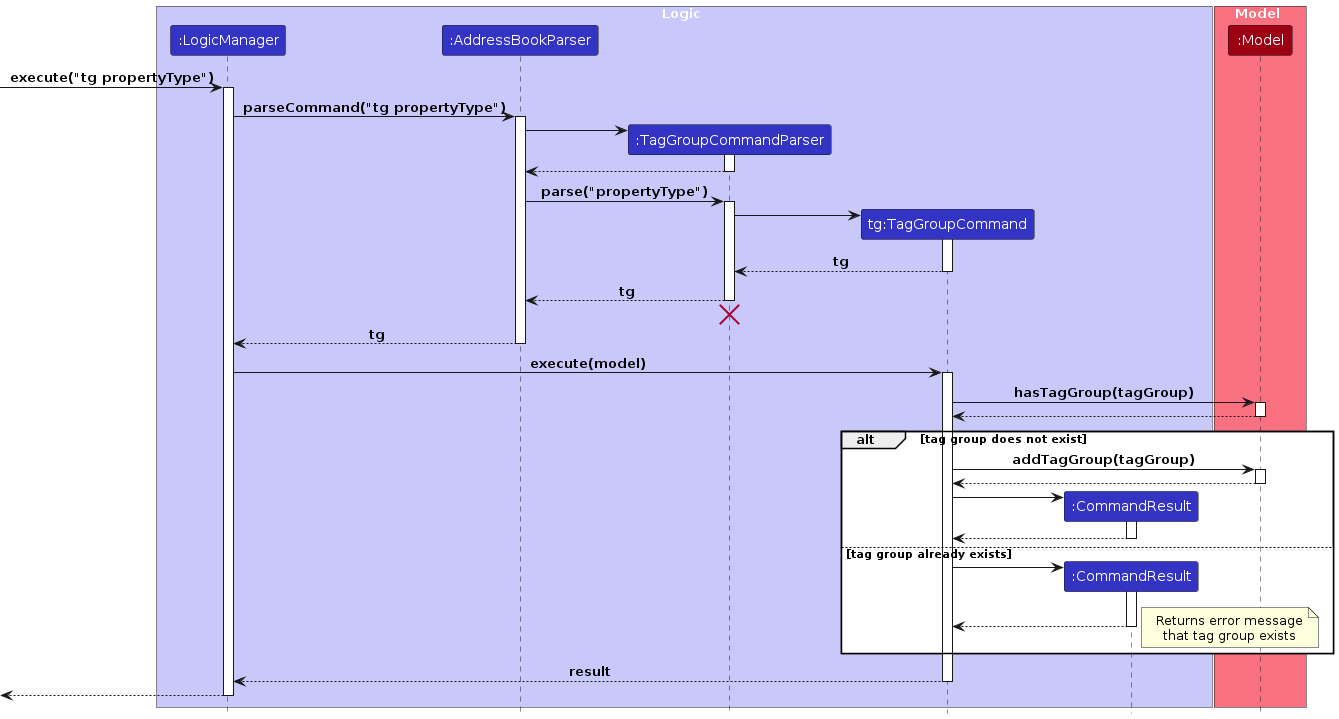
The sequence diagram above illustrates the interaction between Logic and Model components when creating a Tag Group.
Note: The lifeline for TagGroupCommandParser should end at the destroy marker (X) but due to a limitation of PlantUML, the lifeline continues till the end of diagram.
Scenario 2: Listing Tag Groups
User Goal: View all created Tag Groups
Steps:
- User executes
tg(without arguments) AddressBookParsercreates aTagGroupCommandParserTagGroupCommandParserdetects no arguments and creates aTagGroupCommandfor listingTagGroupCommand#execute()retrieves all Tag Groups usingModel#getTagGroupList()- List of Tag Groups is formatted and displayed to the user
Scenario 3: Deleting a Tag Group
User Goal: Delete an unused Tag Group called propertyType
Steps:
- User executes
dtg propertyType AddressBookParsercreates aDeleteTagGroupCommandParserDeleteTagGroupCommandParserparses the input and creates aDeleteTagGroupCommandDeleteTagGroupCommand#execute()performs validation:- Checks if the Tag Group exists using
Model#hasTagGroup() - Checks if it's in use using
Model#isTagGroupInUse()
- Checks if the Tag Group exists using
- If validation passes,
Model#deleteTagGroup()is called - Success message "Tag Group deleted: propertyType" is displayed
Activity Diagram:
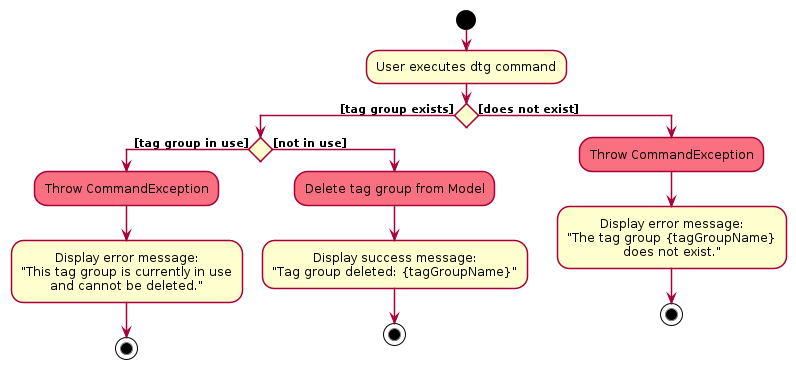
The activity diagram above shows the decision flow when deleting a Tag Group, including validation steps.
Design Considerations:
Aspect: Tag Group Deletion Policy
Alternative 1 (current choice): Prevent deletion if Tag Group is in use
- Pros: Data integrity maintained, prevents orphaned tags
- Cons: Requires manual tag cleanup before group deletion
- Rationale: Chosen to avoid accidental data loss and maintain referential integrity
Alternative 2: Cascade delete all associated tags
- Pros: Simpler workflow for bulk cleanup
- Cons: High risk of unintended data loss, no undo mechanism
Alternative 3: Convert to untagged status
- Pros: Preserves tag associations while removing group
- Cons: Creates inconsistent state, defeats purpose of grouping
Aspect: Tag Group storage structure
Alternative 1 (current choice): Store as a
Set<TagGroup>inAddressBook- Pros: Simple and efficient; automatic duplicate prevention
- Pros: Fast lookup for existence checks (O(1) on average with HashSet)
- Cons: Not ordered; Tag Groups displayed in arbitrary order
Alternative 2: Store as a
Map<String, TagGroup>keyed by Tag Group name- Pros: Slightly faster lookup by name (explicit key-based access)
- Cons: Redundant since
TagGroupalready contains its name - Cons: Requires additional boilerplate code for synchronization
Alternative 3: Store as a sorted list for ordered display
- Pros: Tag Groups displayed in alphabetical order
- Cons: Slower insertion and duplicate checking (O(n))
- Cons: Additional complexity in maintaining sort order
Justification: Alternative 1 was chosen for its simplicity and efficiency. The unordered nature of the Set is not a significant drawback since Tag Groups can be sorted when displayed if needed.
Aspect: Tag and TagGroup relationship design
Alternative 1 (current choice): Tags optionally reference TagGroup; TagGroups don't maintain lists of Tags
- Pros: Simple unidirectional relationship; easier to maintain consistency
- Pros: Tags can exist independently without a group
- Cons: Finding all tags in a group requires scanning all persons' tags
Alternative 2: Bidirectional relationship where TagGroups maintain lists of associated Tags
- Pros: Easy to find all tags in a group
- Cons: Complex bidirectional synchronization required
- Cons: Harder to maintain consistency when tags are added/removed from persons
Justification: Alternative 1 was chosen to minimize complexity and avoid synchronization issues. The use case of "finding all tags in a group" is rare compared to checking if a tag belongs to a group.
Validation Rules
The following validation rules are enforced for Tag Group operations:
Tag Group names:
- Must be alphanumeric (letters and numbers only)
- Cannot contain spaces or special characters
- Validated using regex pattern:
^[a-zA-Z0-9]+$ - Validation occurs in the
TagGroupconstructor
Creating Tag Groups:
- Duplicate Tag Group names are not allowed
- Checked using
Model#hasTagGroup()before adding - Case-sensitive comparison (e.g.
PropertyType≠propertytype)
Deleting Tag Groups:
- Tag Group must exist in the address book
- Tag Group cannot be in use by any person's tags
- Checked using
Model#isTagGroupInUse()which:- Iterates through all persons
- Flattens all tags using
flatMap() - Uses
anyMatch()to check if any tag references the group
Tags with groups:
- Format:
t/GROUP.VALUE(e.g.t/propertyType.HDB) - GROUP (before the dot) must:
- Be alphanumeric only
- Match an existing Tag Group name
- VALUE (after the dot) can contain:
- Alphanumeric characters
- Dots (
.), hyphens (-), and underscores (_) - Must start with an alphanumeric character
- Cannot contain spaces
- Validated during tag parsing using regex patterns in
Tag.isValidTagFormat()
- Format:
Error Handling
The feature implements comprehensive error handling for various edge cases:
| Error Scenario | Command | Error Message |
|---|---|---|
| Invalid Tag Group name (contains spaces) | tg property type | Tag Group names should be alphanumeric |
| Invalid Tag Group name (special chars) | tg property-type! | Tag Group names should be alphanumeric |
| Duplicate Tag Group | tg propertyType (when it exists) | This Tag Group already exists in the address book. |
| Delete non-existent Tag Group | dtg location (doesn't exist) | The Tag Group location does not exist. |
| Delete Tag Group in use | dtg propertyType (when in use) | This Tag Group is currently in use and cannot be deleted. Please remove all tags associated with this group first. |
[Proposed] Undo/redo feature
Proposed Implementation
The proposed undo/redo mechanism is facilitated by VersionedAddressBook. It extends AddressBook with an undo/redo history, stored internally as an addressBookStateList and currentStatePointer. Additionally, it implements the following operations:
VersionedAddressBook#commit()— Saves the current address book state in its history.VersionedAddressBook#undo()— Restores the previous address book state from its history.VersionedAddressBook#redo()— Restores a previously undone address book state from its history.
These operations are exposed in the Model interface as Model#commitAddressBook(), Model#undoAddressBook() and Model#redoAddressBook() respectively.
Given below is an example usage scenario and how the undo/redo mechanism behaves at each step.
Step 1. The user launches the application for the first time. The VersionedAddressBook will be initialized with the initial address book state, and the currentStatePointer pointing to that single address book state.

Step 2. The user executes delete 5 command to delete the 5th person in the address book. The delete command calls Model#commitAddressBook(), causing the modified state of the address book after the delete 5 command executes to be saved in the addressBookStateList, and the currentStatePointer is shifted to the newly inserted address book state.
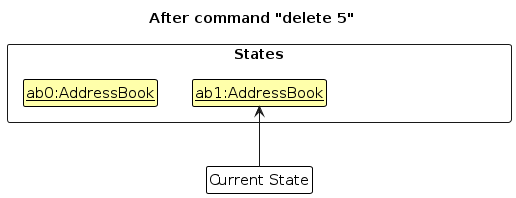
Step 3. The user executes add n/David … to add a new person. The add command also calls Model#commitAddressBook(), causing another modified address book state to be saved into the addressBookStateList.

Note: If a command fails its execution, it will not call Model#commitAddressBook(), so the address book state will not be saved into the addressBookStateList.
Step 4. The user now decides that adding the person was a mistake, and decides to undo that action by executing the undo command. The undo command will call Model#undoAddressBook(), which will shift the currentStatePointer once to the left, pointing it to the previous address book state, and restores the address book to that state.
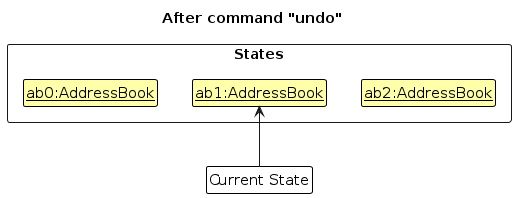
Note: If the currentStatePointer is at index 0, pointing to the initial AddressBook state, then there are no previous AddressBook states to restore. The undo command uses Model#canUndoAddressBook() to check if this is the case. If so, it will return an error to the user rather
than attempting to perform the undo.
The following sequence diagram shows how an undo operation goes through the Logic component:
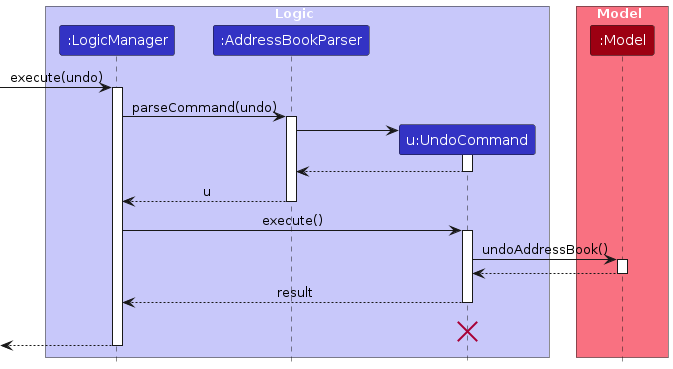
Note: The lifeline for UndoCommand should end at the destroy marker (X) but due to a limitation of PlantUML, the lifeline reaches the end of diagram.
Similarly, how an undo operation goes through the Model component is shown below:
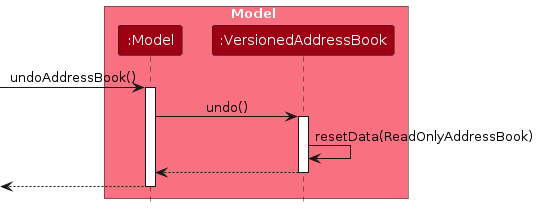
The redo command does the opposite — it calls Model#redoAddressBook(), which shifts the currentStatePointer once to the right, pointing to the previously undone state, and restores the address book to that state.
Note: If the currentStatePointer is at index addressBookStateList.size() - 1, pointing to the latest address book state, then there are no undone AddressBook states to restore. The redo command uses Model#canRedoAddressBook() to check if this is the case. If so, it will return an error to the user rather than attempting to perform the redo.
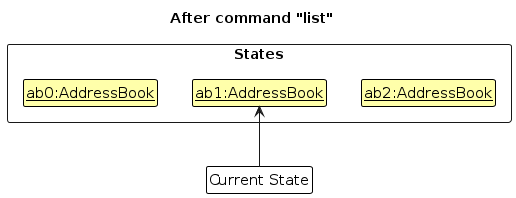
Step 5. The user then decides to execute the command list. Commands that do not modify the address book, such as list, will usually not call Model#commitAddressBook(), Model#undoAddressBook() or Model#redoAddressBook(). Thus, the addressBookStateList remains unchanged.
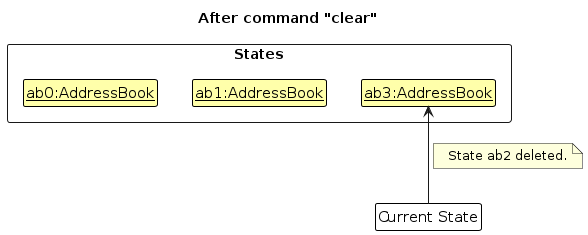
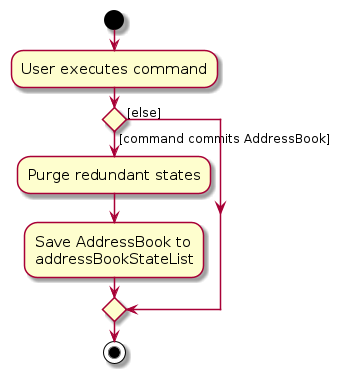
Step 6. The user executes clear, which calls Model#commitAddressBook(). Since the currentStatePointer is not pointing at the end of the addressBookStateList, all address book states after the currentStatePointer will be purged. Reason: It no longer makes sense to redo the add n/David … command. This is the behavior that most modern desktop applications follow.
The following activity diagram summarizes what happens when a user executes a new command:
Design considerations:
Aspect: How undo & redo executes:
Alternative 1 (current choice): Saves the entire address book.
- Pros: Easy to implement.
- Cons: May have performance issues in terms of memory usage.
Alternative 2: Individual command knows how to undo/redo by itself.
- Pros: Will use less memory (e.g. for
delete, just save the person being deleted). - Cons: We must ensure that the implementation of each individual command are correct.
- Pros: Will use less memory (e.g. for
{more aspects and alternatives to be added}
Documentation, logging, testing, configuration, dev-ops
Appendix: Requirements
Product scope
Target user profile:
- is a property agent with many different kinds of contacts
- has a need to manage a big number of contacts
- has a need to track information about each contact
- has a need to categorize different contacts
- prefer desktop apps over other types
- is a fast typist, preferring typing to mouse interactions
- is comfortable using CLI apps
Value proposition: manage and organise different kinds of contacts and their information faster than a typical mouse/GUI driven app
User stories
Priorities: High (must have) - * * *, Medium (nice to have) - * *, Low (unlikely to have) - *
| Priority | As a … | I can … | So that … |
|---|---|---|---|
* * | potential user | see sample contacts | I can expect how the contacts will look like before using the App |
* * * | new user | access help instructions easily | I can refer to instructions when I forget how to use the App |
* * | new user | delete all sample contacts at once | I can start using the app proper quickly |
* * * | new user | view all existing contacts in a list | I can see all my current contacts easily |
* * * | new user | add a new contact with contact information | I can keep track of my growing contacts |
* * * | new user | delete a contact and all its contact information | I can remove contacts I no longer need |
* * * | new user | view a contact's full contact information | I can easily reference all information about a contact |
* * | new user | edit a contact's generic contact information | I can make amends to changes easily |
* * * | new user | assign one or more roles to a contact during creation | I can easily recall my professional relationship with each contact |
* * | new user | delete a role from an existing contact | I can remove roles that no longer apply to the contact |
* * | new user | add a role to an existing contact | I can easily add roles to contacts without having to recreate the whole contact |
* * * | new user | assign a status to a contact during creation | I can track each client's transaction status |
* * | new user | delete a status from an existing contact | I can remove its status if it no longer applies to the contact |
* * | new user | add a status to an existing contact | I can freely decide to track status of contacts at a later time |
* * * | new user | create Tag Groups such as property price or location | I can easily group contacts under business-related categories |
* * * | new user | delete an existing Tag Group | I can clean up Tag Groupings that I no longer want to track about my contacts |
* * | new user | view all existing Tag Groups in a list | I can easily view my current Tag Groups so I do not create duplicates |
* * * | new user | create a contact with grouped tags | I can easily assign a specific tag values within a Tag Group when creating a contact |
* * | new user | create a contact with standalone tags unrelated to any Tag Group | I can still track unique metrics about a contact that do not belong to any Tag Group yet |
* * | expert user | list all client roles | I can understand what types of roles I have already created so far |
* * | expert user | be warned when creating a role that already exists | I can reduce the number of duplicated roles created |
* * | expert user | filter contacts quickly across some roles, status or Tag Groups | I can easily look for specific contacts that match some unique contact information |
* * | expert user | easily record the date and history of each status change | I can easily track when each deal is closed or monitor past transactions |
* | expert user | undo commands quickly | I can quickly rectify mistakes |
* | expert user | redo commands quickly | I can quickly make similar transactions |
* | expert user | apply advanced filters on contacts using boolean-style filtering | I can have finer control over filtering |
* | expert user | filter contacts with substring matching | I can filter more generically if I am unsure of the exact details |
* | expert user | export my contact book | I can migrate my data to other devices |
* | expert user | import existing client data from a csv file | I can start from an existing database |
* * | user with many contacts | find a contact by exact name | I can find if a contact exist without having to go through the entire list |
* * | user with many contacts | find a contact with a substring match of the name | I can find a contact if I forgot how to spell his exact name |
* * | user with many contacts | view statistics of clients grouped by their transaction status | I can quickly see how many clients are pending, completed, or have no status |
Use cases
(For all use cases below, the System is the 'TrackerGuru' and the Actor is the 'Property Agent', unless specified otherwise. The term 'User' will be synonymous with 'Property Agent')
Use case: UC1 - Add a contact
Guarantees
- The address book will not contain duplicate contacts after any operation.
- If the contact is added, all contact information provided by the user will be stored without any loss of information.
MSS
User requests to add a contact.
TrackerGuru saves the contact and its details.
TrackerGuru displays a success message to the user.
Use case ends.
Extensions
- 1a. TrackerGuru detects an error in the entered data (missing required fields or improper format).
- 1a1. TrackerGuru displays an error message and the proper command format to the user. Use case resumes from step 1.
- 1b. TrackerGuru detects a duplicate contact (same phone number or email).
- 1b1. TrackerGuru displays an error message. Use case ends.
- 1c. Contact uses a Tag Group that has not been created yet.
- 1c1. TrackerGuru displays message informing user to create the tag group first.
- 1c2. User Creates a Tag Group (UC6). Use case resumes from step 1.
Use case: UC2 - Delete a contact
MSS
User requests to delete a contact.
TrackerGuru deletes the contact.
TrackerGuru displays a success message to the user.
Use case ends.
Extensions
- 1a. TrackerGuru detects that the contact’s unique identifier is missing in the entered data.
- 1a1. TrackerGuru requests for the contact’s unique identifier. Use case resumes from step 1.
- 1b. TrackerGuru cannot find the specified contact’s unique identifier.
- 1b1. TrackerGuru requests for a valid unique identifier.
- 1b2. User enters a new unique identifier.
- 1b3. Steps 1b1–1b2 are repeated until the unique identifier is one that exists. Use case resumes from step 2.
Use case: UC3 - Filter contacts by roles, statuses, and Tag Groups
Guarantees
- The filtered list will only contain contacts that match any of the specified filter criteria.
- The original contact data remains unchanged after filtering.
MSS
User requests to filter contacts by specifying one or more criteria such as role, status, and/or Tag Group.
TrackerGuru processes the filter criteria and retrieves matching contacts.
TrackerGuru displays the filtered list of contacts to the user.
Use case ends.
Extensions
- 1a. TrackerGuru detects error in entered command.
- 1a1. TrackerGuru displays an error message and the correct command format. Use case resumes from step 1.
Use case: UC4 - Search contact by name
Guarantees
- Only contacts whose names match the given keywords will be displayed to the user (if MSS completes).
- Contact information will not be modified.
MSS
User requests for contacts whose name matches the given keywords.
TrackerGuru displays all matching contacts.
TrackerGuru displays a success message to the user.
Use case ends.
Extensions
- 1a. TrackerGuru detects an error in the entered data (missing required fields or improper format).
- 1a1. TrackerGuru displays an error message and proper command format to the user. Use case resumes from step 1.
Use case: UC5 Edit a contact
Guarantees
- Existing contact information will be updated to the address book only if MSS completes.
- All the field values in the contact will be valid.
MSS
User requests to edit contact with updated details.
TrackerGuru edits and saves the updated contact information.
TrackerGuru displays success message to the user.
TrackerGuru's contact list reflects the updated contact information.
Use case ends.
Extensions
- 1a. TrackerGuru detects an error in the entered data.
- 1a1. TrackerGuru displays error message with the expected command usage. Use case resumes from step 1.
Use case: UC6 - Create a Tag Group
Guarantees
- Each Tag Group created will have a unique name within the address book.
- Once created, the Tag Group will be available for assigning tags to contacts.
MSS
User requests to create a Tag Group.
TrackerGuru saves the Tag Group name.
TrackerGuru displays a success message to the user.
Use case ends.
Extensions
- 1a. TrackerGuru detects that the Tag Group name is missing or improperly formatted.
- 1a1. TrackerGuru displays an error message and shows the correct command format. Use case resumes from step 1.
- 1b. TrackerGuru detects a duplicate Tag Group name.
- 1b1. TrackerGuru displays an error message indicating that the Tag Group already exists. Use case ends.
Non-Functional Requirements
Performance/Capacity requirements
- The system should be able to store up to 200 contacts at once
- The system should load and display contact lists within 2 seconds, even at maximum capacity
- The system should boot within 3 seconds on a computer with at least 8GB RAM and an Intel Core i5/Ryzen 5-class processor (or equivalent)
Technical requirements
- The system should work on any computer that runs Java 17
- The system should not have a remote server
- The system should be functional without internet connection
- The system should only use local storage to store contacts
- The system should support using a local .json file to store and retrieve contact data
Reliability requirements
- The system should not lose saved data in the event of unexpected termination
Security requirements
- The system should not transmit contact data over the internet
Maintainability requirements
- The code should be modular and well documented
- The system should allow adding new contact fields without major refactoring
Quality requirements
- The system should provide help and usage instructions
- Command syntax should be consistent and documented
- All operations can be completed in no more than one typed line
- The system should display clear error messages for invalid inputs instead of crashing
Glossary
- address book: The collection of all contacts and their associated data stored in TrackerGuru, persisted locally as a JSON file
- client: A specific type of contact that represents customers of the property agent (i.e. property buyers, sellers, landlords, tenants)
- contact information: Exact contact details of a person; name, phone number, email, address
- role: A field that defines the function or relationship of a contact (e.g. buyer, seller, landlord, tenant) in the property business
- status: A label indicating the current state of a client transaction (e.g. Pending, Completed).
- tag: A simple standalone label used to categorize or describe a contact
- grouped tag: A label described by a tag value belonging to a Tag Group
- Tag Group: A category for organizing related tags together (e.g. "PropertyType", "Location"), enabling structured tag management and group-based filtering of contacts
- tag value: A specific value of a Tag Group (e.g. "Condo" of "PropertyType")
- sample contact: Preloaded example contacts provided in TrackerGuru to help new users explore app features before entering their own data
- help instructions: User guide in the TrackerGuru webpage to assist users in learning how to use the app
- new user: A first-time user of TrackerGuru who has not yet created any personal contacts
- expert user: A user who is already familiar with TrackerGuru’s features and performs advanced operations such as complex filtering or data management
- boolean-style filtering: A method to filter contacts by combining multiple criteria precisely using AND ("match all") and OR ("match any") logic (e.g. filter contacts that have a specific role AND a certain status, or contacts that have a specific tag)
- substring match: A method to match a contact as long as the search term is anywhere within the target field (e.g. 'b' can match 'buyer')
Appendix: Instructions for Manual Testing
The following are sample instructions for manually testing TrackerGuru. They serve as a starting point; you are encouraged to perform exploratory testing beyond these examples to uncover edge cases.
Note: Each test case includes the command to execute and the expected outcome. Testers should verify that error and success messages match the described behavior.
Launch and shutdown
Initial launch
Download the
.jarfile and place it into an empty folder.Double-click the file to launch.
Expected: The GUI opens with sample contacts loaded. The window size may not be optimal initially.
Saving window preferences
Resize the window and move it to a different location. Close the window.
- Close and relaunch the application by double-clicking the
.jarfile
Expected: The previous window size and location are retained.
- Close and relaunch the application by double-clicking the
Deleting a person
Deleting While All Persons Are Shown
Prerequisites: Use
listcommand to show all persons. Ensure there are multiple persons listed.Test case:
delete 1
Expected: The first contact is deleted. The status message shows details of the deleted person.Test case:
delete 0
Expected: Error message shown. No person is deleted.Other invalid commands to try:
delete,delete x(wherex> list size)
Expected: Error message displayed. No changes to list.
Creating and managing Tag Groups
Creating a New Tag Group
Test case:
tg PropertyType
Expected: Tag Group "PropertyType" created successfully. Confirmation message shown.Test case:
tg PropertyType
Expected: Error message shown indicating the Tag Group already exists.Test case:
tg Property Type(with space)
Expected: Error message shown indicating Tag Group names must be alphanumeric with no blanks.Test case:
tg
Expected: A list of all your created Tag Groups.Other invalid commands to try:
tg tag-Group,tg tagGroup 123!
Expected: Error message about invalid format.
Deleting a Tag Group
Prerequisites: Create a Tag Group
Locationusingtg Locationthat is not referenced by any contact's tags. Usetg Property Typeand add a tag of this Tag Group to the first contact usingedit 1 t/PropertyType.HDBTest case:
dtg Location
Expected: Tag Group "Location" is deleted. Success message shown.Test case:
dtg PropertyType
Expected: Error message indicating the Tag Group is in use and cannot be deleted.Test case:
dtg NonExistent
Expected: Error message indicating Tag Group does not exist.Other invalid commands to try:
dtg,dtg 123!
Expected: Error message about invalid format.
Using tags with Tag Groups
Prerequisites: Create a Tag Group "PropertyType" using
tg PropertyType.Test case: Add contact with grouped tag:
add n/John Doe p/98765432 e/johnd@example.com a/123 Street r/Buyer t/PropertyType.HDB
Expected: Contact added with tag "PropertyType.HDB". Success message shown.Test case: Add contact with tag referencing non-existent group:
add n/Jane Doe p/98765433 e/janed@example.com a/456 Street r/Seller t/Nonexistent.Condo
Expected: Error message indicating Tag Group "Nonexistent" does not exist.
Creating and managing roles
- Adding roles to a person
Prerequisites: List all persons using the
listcommand. There should be multiple persons in the list.Test case:
edit 1 r/BuyerExpected: The first contact’s role list is replaced with a single role “Buyer”. Success message shown.Test case:
edit 1 r/Buyer r/InvestorExpected: The first contact’s roles are replaced with “Buyer” and “Investor”. Success message shown.Test case:
edit 1 r/Expected: All roles are removed from the first contact. Success message shown.Test case:
edit 1 r/_Admin or edit 1 r/-LeaderExpected: Error message indicating that roles cannot start with hyphen or underscore.Other incorrect commands to try:
edit 1 r/Inval!dExpected: Error message about invalid role format.
Filtering by Tag Groups, status or roles
Basic filtering
Prerequisites:
- Create Tag Groups
PropertyTypeandLocation. - Add tags
t/PropertyType.HDB,t/Location.Eastto some contacts. - Add roles
Buyer,Seller,Investorto some contacts. - Assign statuses
PendingandCompletedto some contacts.
- Create Tag Groups
Test case:
filter tg/PropertyTypeExpected: Lists all contacts with the “PropertyType.HDB” tag.Test case:
filter r/BuyerExpected: Lists all contacts with the “Buyer” role (case-insensitive).Test case:
filter s/PendingExpected: Lists all contacts with status “Pending” (case-insensitive).
Multiple filter fields
Test case:
filter tg/PropertyType tg/LocationExpected: Shows contacts that have tags from either Tag Groups.Test case:
filter r/Buyer r/InvestorExpected: Shows contacts that have either roles.Test case:
filter s/Pending s/CompletedExpected: Shows contacts with either status.Test case:
filter tg/PropertyType r/Buyer s/PendingExpected: Lists only contacts that satisfy either criteria: Tag GroupPropertyType, roleBuyer, and statusPending.
Invalid and edge cases
Test case:
filterExpected: Error message shown.Test case:
filter tg/orfilter r/orfilter s/Expected: Error message shown, filter values must be specified.Test case:
filter tg/UnknownGroup r/UnknownRoleExpected: No contacts shown, success message with empty list.
Saving data
Dealing with missing/corrupted data files
Simulating a corrupted data file:
- Locate the data file at
[JAR file location]/data/addressbook.json - Open it with a text editor
- Delete a random closing brace
}or bracket] - Save and close the file
- Relaunch TrackerGuru
Expected: TrackerGuru starts with an empty address book and shows a warning message about corrupted data. The corrupted file is not overwritten, unless the user executes any commands that modify the empty address book.
- Locate the data file at
Simulating a missing data file:
- Delete the
addressbook.jsonfile from thedatafolder - Relaunch TrackerGuru
Expected: TrackerGuru starts with sample contacts (default data).
- Delete the
Simulating invalid Tag Group references:
- Open
addressbook.json - Find a person with a tag like
"PropertyType.HDB" - In the
tagGroupsarray, delete the{"tagGroupName": "PropertyType"}entry - Save and relaunch
Expected: For data resilience, TrackerGuru commands still work normally with Tag Group
PropertyTypeand does not affect normal operations. Only when listing usingtg,PropertyTypewill not appear.- Open
Appendix: Planned Enhancements
Team size: 5
Allow Optional Contact Fields in Add Command: Currently, the add command requires all four fields (name, phone, email, address) to be provided:
add n/John Doe p/98765432 e/johnd@example.com a/123 Street.We plan to make phone, email and address optional, allowing commands like add n/John Doe p/98765432 where missing fields display as "N/A".Support Incremental Editing for Roles, Statuses, and Tags: Currently, edit 1 r/Investor replaces all existing roles, causing data loss if the contact previously had roles like [Buyer] [Seller]. We plan to introduce new prefixes:
r+/Investorto add roles,r-/Buyerto remove specific roles, and keepr/Agentfor replacing all roles. The same syntax will apply to tags (t+/, t-/) and status (s+/, s-/).Improve Handling of Corrupted or Invalid Data Entries: Currently, when corrupted or invalid data is detected in the storage file, the application throws a warning and loads an empty storage file. We plan to enhance this by detecting, isolating and reporting only the corrupted entries during data loading. The application will retain and process all valid data while displaying clear warnings that specify which entries are corrupted and why. This improvement increases data resilience, usability and debugging efficiency.
Separate Command for Listing Tag Groups: Currently, the tg command has dual behavior -
tg TAGGROUP_NAMEcreates a Tag Group whiletg(without arguments) lists all existing Tag Groups. This dual behavior can be confusing as the same command does different things based on whether arguments are provided. We plan to introduce a separate ltg command specifically for listing Tag Groups.- Current behavior:
tg PropertyType→ Creates Tag Group "PropertyType"tg→ Lists all Tag Groups
- Planned behavior:
tg PropertyType→ Creates Tag Group "PropertyType" (unchanged)ltg→ Lists all Tag Groupstg→ Shows error message directing users to use ltg for listing
- Current behavior:
Appendix: Effort
Difficulty Level
TrackerGuru required approximately 50% of effort spent on creating AB3 due to:
- Multiple new features (Tag Groups, Role, Status, filtering, statistics)
- Extensive Model and Storage refactoring, particularly for the two-tier Tag Group architecture that transformed AB3's simple flat tag structure into a hierarchical categorisation system
- Multi-layer validation logic with flexible regex patterns
- Feature integration challenges
Challenges Faced
1. Tag Group System Implementation
Implementing a system supporting both grouped tags (PropertyType.HDB) and standalone tags (Urgent) was complex and represented a significant architectural departure from AB3's simple tag structure.
Key issues:
- Deciding how
TagandTagGroupshould connect to each other while keeping data consistent across all parts of the app - Handling what happens when users delete a Tag Group that tags are using without losing user data
- Saving and loading Tag Groups from JSON files which required creating a new storage adapter class
- Balancing strict input rules with flexibility by using different validation patterns: GROUP names are letters/numbers only, but VALUES can include dots, hyphens, and underscores for real property data like
price.1.5M-2M - Preventing deletion of Tag Groups currently in use by checking all contacts efficiently
Solution: Made Tag reference TagGroup in one direction only, implemented graceful fallback when Tag Groups are missing, and created JsonAdaptedTagGroup for file storage. Updated AddressBook and ModelManager with methods to manage Tag Groups (addTagGroup(), deleteTagGroup(), hasTagGroup(), listTagGroups()) and added validation in AddCommand/EditCommand to check Tag Groups exist before saving contacts.
2. Duplicate Field Detection
Implementing duplicate phone/email detection across add and edit operations required careful design.
Key issues:
- Cascading checks through multiple layers (AddCommand → ModelManager → AddressBook → UniquePersonList)
- Incorrect duplicate handling logic
Solution: Implemented hasSamePhoneNumber() and hasSameEmail() at each Model layer using Java Streams for efficiency and changed the duplicate handling logic to check for duplicate phone number and email.
3. Multi-Criteria Filtering
The filter command needed to support OR logic across Tag Groups, roles, and statuses.
Key issues:
- Combining multiple predicate types efficiently
- Handling non-existent filter values (should not error for roles/statuses but should for Tag Groups)
- Updating JavaFX
ObservableListreactively
Solution: Created specialised predicate classes and combined them with more lenient "or" logic
4. Tag Group Deletion Validation
Preventing deletion of in-use Tag Groups required scanning all contacts efficiently.
Key issues:
- Checking all persons and their tags for Tag Group references
- Performance with many contacts
- Clear error messages when deletion blocked
Solution: Used Model#isTagGroupInUse() to check all contacts in one pass for better performance.
Achievements
Domain-Specific Features: Transformed AB3 into a specialized property agent tool with organised Tag Groups that work like folders for categorizing tags (e.g. propertyType.HDB), roles, statuses, filtering, and statistics.
Data Integrity: Implemented duplicate detection for phone/email, comprehensive Tag Group validation that accepts flexible real-world formats, and graceful handling of corrupted data including handling missing Tag Group references.
Code Quality: Maintained clean architecture with proper separation between different parts of the app, comprehensive test coverage, and extensive documentation.
Reuse and Adaptation
- Reused: UI components, Storage infrastructure, Command framework
- Adapted:
Model(Tag Groups, duplicate detection),Logic(new parsers/commands),UniquePersonList(duplicate checking) - New: Tag Group feature, Statistics, Filtering system, Duplicate field handling